目前我们处于RAG的2.0进化到3.0的过程中。即从2.0的多路查询混合检索,检索结果重排序等机制,到检索和多步推理结合的RAG3.0时代,解决RAG不仅是检索,更是思考的难题
摘要:
抛出一些基础问题
- 相似性=相关性吗
- rerank 排序的依据是什么
- 是什么疑问嵌入模型和上下文嵌入模型,那种更好
- 如何评估rag的效果
01-1RAG的系统流程
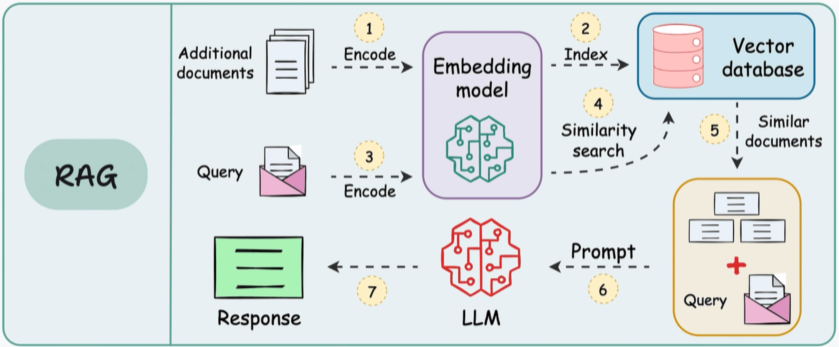
01-1.1 外部数据
RaG数据治理也会有一些反常识,比如随着数据的增加,性能指标先上升后下降,然后再上升,还有有时增加跟已有数据完全不相关的数据,反而会激活和提升rag准召率。
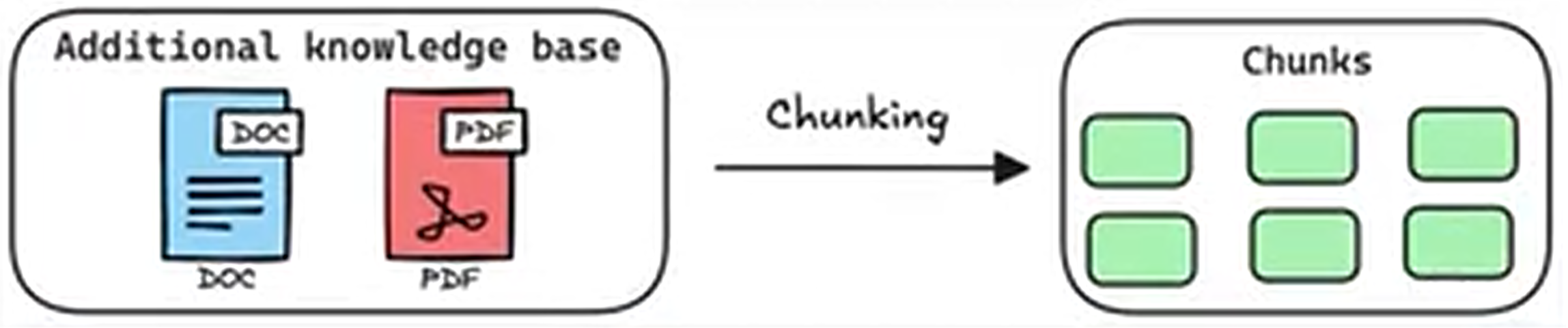
 数据的复杂性还包括如下两方面,第一,数据的来源五花八门,比如网页、书籍、百科代码、其他等等各种渠道。第二,数据加工流程的繁琐,比如正文提取、质量过滤文档、去重降噪、数据集净化等等。
此外你还要考虑数据收集渠道的局限性,数据的多样性、个人的主观性、数据规模及评估数据质量等等。
数据治理对我来说是一门工程,我称之为数据工程。既然是工程,就一定有对应的方法论和实施标准。坚定的给领导和客户洗脑,刚开始的时候就洗。我会告诉他们数据就是AI性能的天花板,加强需求方对数据的重视程度,以及做好客户的预期管理,文档数据准备好,我们就进入了第二步,创建分块。
数据的复杂性还包括如下两方面,第一,数据的来源五花八门,比如网页、书籍、百科代码、其他等等各种渠道。第二,数据加工流程的繁琐,比如正文提取、质量过滤文档、去重降噪、数据集净化等等。
此外你还要考虑数据收集渠道的局限性,数据的多样性、个人的主观性、数据规模及评估数据质量等等。
数据治理对我来说是一门工程,我称之为数据工程。既然是工程,就一定有对应的方法论和实施标准。坚定的给领导和客户洗脑,刚开始的时候就洗。我会告诉他们数据就是AI性能的天花板,加强需求方对数据的重视程度,以及做好客户的预期管理,文档数据准备好,我们就进入了第二步,创建分块。
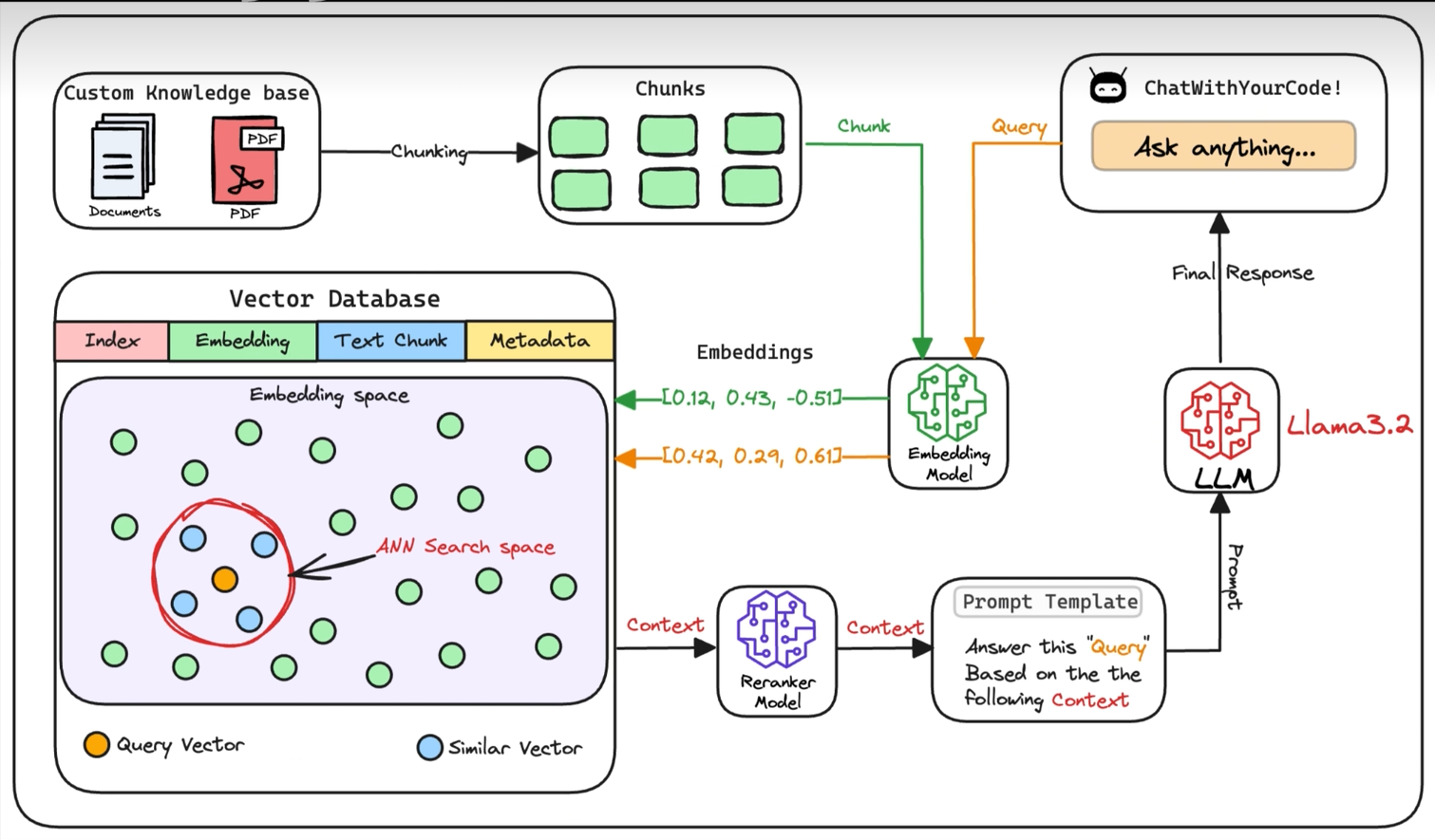
01-1.2 文档分块
 分块的必要性,即满足嵌入模型要求和提升检索效果。原因是不分块,文档只有一个嵌入向量,不具备任何检索的条件。同时不分块,自身的体积过大,无法大满足嵌入模型的要求。
分块的必要性,即满足嵌入模型要求和提升检索效果。原因是不分块,文档只有一个嵌入向量,不具备任何检索的条件。同时不分块,自身的体积过大,无法大满足嵌入模型的要求。
分块的五种策略
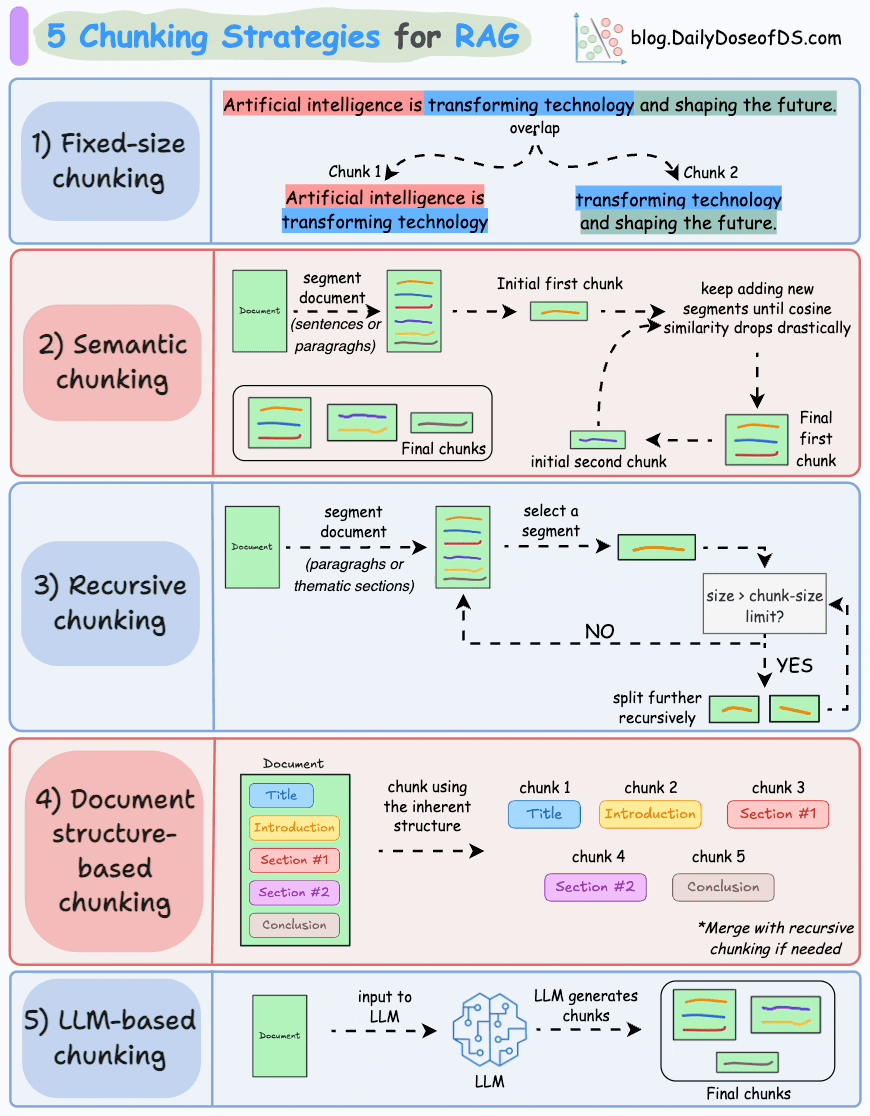
1. 第一个就是固定大小的分块, 2. 语义分块 3. 递归分块 4. 基于文档结构的分块 5. 过大模型给我们做分块
01-1.3 嵌入模型
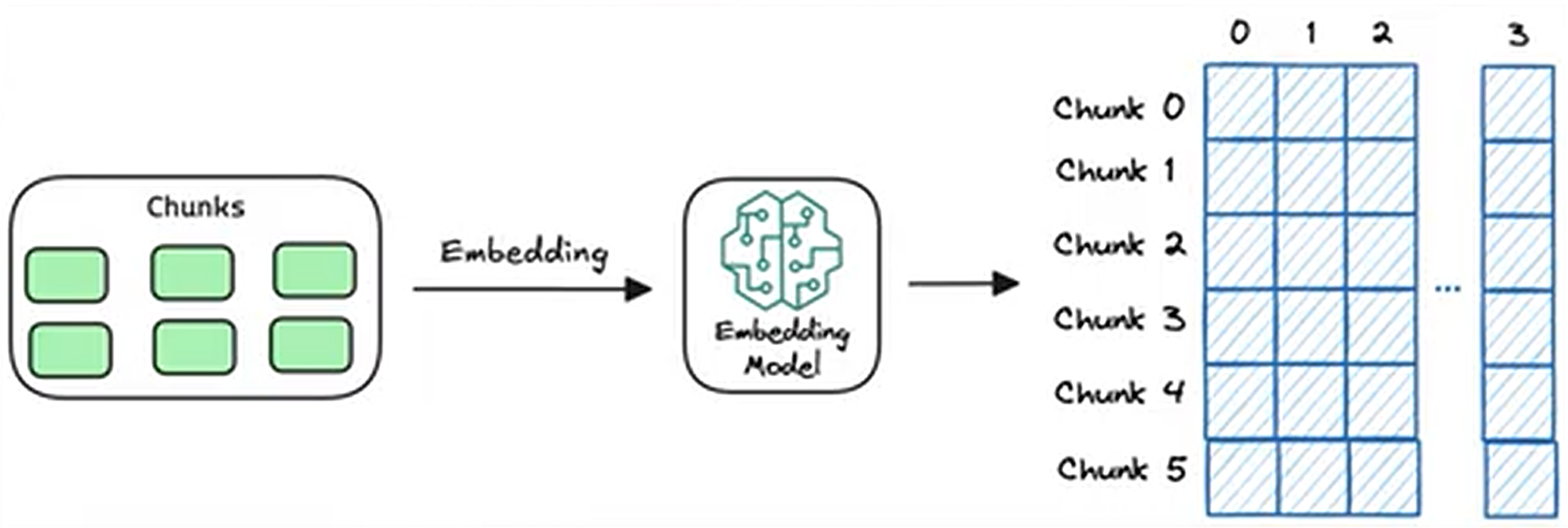 词嵌入和句嵌入,把文字转化为数学向量,大致在13-17年大量词嵌入模型(glove、word2vec等静态模型)涌现,但是存在问题词语语境不同会有多种含义。
后来这个问题在Transformer时代得到解决,产生了由Transformer驱动的上下文嵌入模型,比知:BERT、DStiIBERT、ALBERT等.
词嵌入和句嵌入,把文字转化为数学向量,大致在13-17年大量词嵌入模型(glove、word2vec等静态模型)涌现,但是存在问题词语语境不同会有多种含义。
后来这个问题在Transformer时代得到解决,产生了由Transformer驱动的上下文嵌入模型,比知:BERT、DStiIBERT、ALBERT等.