在上一篇《战术篇(上)》中,我们掌握了为结构化与半结构化知识”精雕细琢”的武器。我们学会了如何利用文档的内在结构(如Markdown标题、HTML标签)来实现精准切分。然而,企业知识的版图中,还存在着更具挑战性的领域——它们如流沙般无形,如矿藏般深藏,这便是非结构化文本与代码知识。
欢迎来到技术深潜的第二站。本篇,我们将直面最棘手的场景,学习如何”披沙拣金”,从看似混乱的信息中提炼出真正的价值。我们将聚焦于:
-
非结构化文本:如客服对话、用户评论、会议纪要等,这类文本缺乏明确的结构,但蕴含着最直接的用户声音和业务洞察。
-
代码知识:作为技术公司的核心资产,代码库本身就是一个巨大的知识库,但其结构由编程语法定义,传统的文本处理方法难以奏效。
为此,我们将解锁武器库中更为高级和专门化的三件利器:
-
语义切片 (Semantic Chunking):超越规则,读懂文字”言外之意”的读心者。
-
滑动窗口与元数据增强 (Sliding Window & Metadata Augmentation):为时序对话保留关键上下文的记忆锚点。
-
代码感知切片 (Code-Aware Chunking):深入代码脉络,像开发者一样理解代码的解构师。
准备工作:环境回顾
我们将继续使用 langchain 生态进行实战。请确保你已安装好必要的库,并设置好你的OpenAI API密钥。
# 核心库
pip install -q langchain langchain_community langchain_openai
# 向量化与存储
pip install -q faiss-cpu tiktoken
# 语义切片需要用到
pip install -q langchain_experimental
import os
from langchain_openai import OpenAIEmbeddings
# 建议使用环境变量来管理你的API密钥
# os.environ["OPENAI_API_KEY"] = "sk-..."
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
武器一:语义切片 (Semantic Chunking) - 读心者
对于非结构化文本,我们面临的核心挑战是:文本的逻辑边界隐藏在语义中,而非显式的格式里。一个用户评论可能会在一段之内,从事实陈述转到情绪表达,再到功能建议。传统的递归切片可能会在这里”迷路”。
语义切片正是为此而生。它是一种更高级的分割技术,其工作原理是:
-
将文本打散成单个句子。
-
为每个句子生成嵌入向量(Embedding)。
-
计算相邻句子嵌入向量之间的语义相似度(通常是余弦相似度)。
-
当相似度出现一个”断崖式”下跌时,就认为这里发生了一个语义中断,并在此处进行切分。
这就像一个”读心者”,它不关心换行符或段落符,只关心内容的意义流是否发生了转变。
代码实战:
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# 一段主题连续变化的非结构化文本
unstructured_text = """
我们的新功能上线后,初期反响热烈。许多用户称赞了其创新的交互设计和流畅的用户体验。
一位来自加州的用户反馈说,这个功能为他的日常工作节省了大量时间。
然而,随着使用量的增加,一些问题也逐渐暴露出来。
部分用户报告在低配设备上存在性能问题,主要表现为加载缓慢和偶尔的卡顿。
我们技术团队正在紧急排查,初步定位是内存管理方面需要优化。
我们承诺将在下个版本中解决这个问题,并对受影响的用户表示歉歉。
"""
# 初始化语义切片器
# percentile_threshold: 设置语义中断的阈值。可以是百分比(95%),也可以是绝对值。
# 值越低,切分得越细碎;值越高,切分得越大块。
text_splitter = SemanticChunker(
OpenAIEmbeddings(model="text-embedding-3-small"),
breakpoint_threshold_type="percentile", # 使用百分位阈值
breakpoint_threshold_amount=95
)
chunks = text_splitter.create_documents([unstructured_text])
# 看看切分结果
for i, chunk in enumerate(chunks):
print(f"--- 块 {i+1} ---")
print(chunk.page_content)
print()
<img
src=“https://raw.githubusercontent.com/lilbitty007/obs_img/%E5%88%86%E6%94%AF1/img/20250627213008520.png”alt=“图片描述” style=“display: block; margin: 0 auto;” width=“600”>
“语义中断”是如何被发现的?—— **breakpoint_threshold_type** 参数详解
{kind=link}
SemanticChunker 的”魔法”在于它如何决定在何处切分,而这背后的”秘密”就藏在breakpoint_threshold_type这个参数里。它定义了我们如何从一堆句子相似度得分中,找到那个”异常高”的突变点。
LangChain 提供了几种统计方法来做这件事:
**gradient**(梯度)
-
原理: 这是最能体现”语义断崖”这个概念的方法。它将相邻句子的相似度得分看作一个序列,然后计算这个序列的”梯度”,也就是变化率。当相似度从一个高点突然下跌到一个低点时,这个变化率(梯度)的绝对值会非常大。该方法会直接找到梯度变化最剧烈的那些点作为切分点。
-
优点: 非常直观地捕捉了语义焦点的突然转变,对于识别话题的硬性切换非常有效。
**percentile**(百分位,默认方法)
-
原理: 这是最直观和常用的方法。它首先计算出所有相邻句子之间的”语义距离”(1 - 相似度,距离越大代表越不相关)。然后,它根据这些距离的分布,来设定一个阈值。例如,
breakpoint_threshold_amount=95的意思是:“将所有距离中,排在前5%的那些最大距离作为切分点”。 -
优点: 适应性强。对于一篇整体内容连贯、主题单一的文档(句子间距离普遍较小),它会自动采用一个较低的距离阈值来切分;反之,对于主题跳跃的文档,它会采用一个较高的阈值。
**standard_deviation**(标准差)
-
原理: 这是一个经典的统计学方法,用于寻找离群值。它会计算所有句子间距离的平均值(mean)和标准差(std)。如果某个距离大于
mean + n * std(这里的n就是breakpoint_threshold_amount),它就被认为是一个”异常”的语义中断,并在此处切分。 -
优点: 基于数据的正态分布假设,对于分布较均匀的数据效果很好。
**interquartile**(四分位数)
-
原理: 这种方法比标准差更稳健,尤其是在数据中存在极端异常值时。它使用四分位距(IQR)来定义”异常”。一个切分点被定义为任何距离大于
第三四分位数 (Q3) + n * IQR的地方。 -
优点: 对极端离群值的存在不敏感,鲁棒性更强。
通过理解这些参数,我们就从一个使用者,变成了一个能够根据不同文档特性,精细调优切片策略的专家。
深度剖析:语义切片 vs. 传统切片
为了真正理解语义切片的威力,我们不仅要看它做了什么,更要理解它为什么如此重要。这关乎一个核心概念:上下文的纯净度 (Context Purity)。一个”纯净”的块,其内部所有句子的主题都高度统一。
让我们用一个更具体的对比,来展示它与传统递归切片(RecursiveCharacterTextSplitter)在RAG流程中的天壤之别。
| 特性 | RecursiveCharacterTextSplitter (基于规则) | SemanticChunker (基于语义) |
|---|---|---|
| 切分依据 | 预定义的字符(如\\n\\n, .)和块大小限制。 | 相邻句子间的语义相似度突变。 |
| 切分结果 | 块的长度相对均匀,但可能在语义连贯的段落中间被”拦腰斩断”。 | 块的长度不一,但每个块在主题上高度内聚和完整。 |
| 上下文纯净度 | 较低。一个块可能包含多个主题的片段。 | 极高。一个块只专注于一个主题。 |
RAG问答场景下的具体影响
假设用户的提问是:“新功能主要有什么性能问题?”
- 使用
**RecursiveCharacterTextSplitter**的世界:
-
切分:它可能会按照段落符,将原文切成三块。第二块可能包含”…一些问题也逐渐暴露出来。部分用户报告在低配设备上存在性能问题…”,但它的开头可能还连着上一段的”正面反馈”,结尾可能连着下一段的”技术团队排查”。
-
检索:用户的提问向量与这三个块计算相似度。第二块的得分最高,但可能第一块和第三块也有一定的分数,因为它们也提到了”新功能”。系统可能会返回第二块,甚至会把第一块也作为相关内容返回。
-
生成:LLM得到的上下文是”…用户称赞…一些问题…性能问题…技术团队排查…”。这个上下文是被污染的,包含了正面反馈和解决方案,并非纯粹的问题描述。LLM需要付出额外的”认知努力”来从中筛选出回答”性能问题”所需要的信息,增加了出错或生成冗余回答的风险。
- 使用
**SemanticChunker**的世界:
-
切分:它识别出”正面反馈”、“问题报告”、“解决方案”是三个独立的语义单元,并以此为边界切分。
-
检索:用户的提问向量与”问题报告”这个块的向量高度匹配,相似度得分远高于另外两个块。系统会以极高的置信度只返回这一个块。
-
生成:LLM得到的上下文是:“部分用户报告在低配设备上存在性能问题,主要表现为加载缓慢和偶尔的卡顿。” 这是一个高度纯净、100%相关的上下文。LLM可以毫不费力地直接基于此信息生成精准的答案。
结论:语义切片的核心优势在于,它在RAG流程的最前端(切分阶段)就保证了知识的纯净度和高质量。这种前端的”精加工”极大地降低了后端检索和生成环节的难度和模糊性,从而系统性地提升了RAG应用的整体表现。
召回策略:纯粹的语义力量
由于语义切片天然保证了每个块在主题上的高度内聚,其最主要的召回方式就是纯粹的向量相似度搜索。
工作流如下:
-
提问: 用户提出问题,如”新功能有什么性能问题?”
-
查询向量化: 将用户问题通过相同的嵌入模型(
text-embedding-3-small)转换为查询向量。 -
向量检索: 在向量数据库中,计算查询向量与所有文本块向量之间的余弦相似度。
-
返回结果: 返回相似度最高的Top-K个块。
因为块的内容是围绕单一主题(例如”性能问题报告”)组织的,所以检索到的结果将非常精准,包含的噪声信息极少。这就像是与一位一次只谈论一个话题的专家对话,沟通效率极高。
武器二:滑动窗口(Sliding Window)-对话记忆锚点
在处理客服对话、会议纪要这类时序性强的文本时,最大的挑战是上下文的连续性。一个问题的答案可能出现在几轮对话之前。如果我们将每一轮对话都切成独立的块,LLM就会丢失这种上下文,变成一个“金鱼记忆”的机器人。
滑动窗口是解决这个问题的经典策略。他通过在块之间引入重叠(overlap),来确保每个块都”记得“前面发生过什么。
更进一步,我们可以结合元数据增强(Metadata Augmentation),为对话场景打造终极武器。
工作原理
- 按轮次切分:首先,将对话按发言人或时间戳分割成一个个独立的单元。
- 添加元数据:为每个单元添加结构化的元数据,如
speak(发言人)、timetamp(时间戳) - 滑动窗口组合:使用一个“窗口”将多个连续的对话单元组合成一个块,例如-一个大小为3的窗口,会将第1、2、3轮对话合并为块1,第2、3、4轮对话合并为块2,以此类推。
代码实战
# 这是一个概念性的演示,LangChain中可以通过自定义逻辑实现
# 原始对话记录
dialogue = [
{"speaker": "User", "timestamp": "10:01", "text": "你好,我的订单好像延迟了。"},
{"speaker": "Support", "timestamp": "10:02", "text": "您好,请问能提供一下您的订单号吗?"},
{"speaker": "User", "timestamp": "10:03", "text": "当然,是 #12345。"},
{"speaker": "Support", "timestamp": "10:04", "text": "感谢。我查一下... 好的,看到您的订单了。"},
{"speaker": "Support", "timestamp": "10:05", "text": "确实有些延迟,原因是物流出现了一些意外情况。我们预计明天可以送达。"},
{"speaker": "User", "timestamp": "10:06", "text": "好的,谢谢你。"},
]
def sliding_window_chunking_with_metadata(dialogue, window_size=3):
chunks = []
for i in range(len(dialogue) - window_size + 1):
window = dialogue[i : i + window_size]
# 将窗口内的对话文本合并
content = "\\n".join([f"[{turn['timestamp']}] {turn['speaker']}: {turn['text']}" for turn in window])
# 元数据可以包含窗口的起始信息
metadata = {
"start_timestamp": window[0]['timestamp'],
"end_timestamp": window[-1]['timestamp'],
"participants": list(set(turn['speaker'] for turn in window))
}
chunks.append({"content": content, "metadata": metadata})
return chunks
dialogue_chunks = sliding_window_chunking_with_metadata(dialogue)
# 看看切分结果
for i, chunk in enumerate(dialogue_chunks):
print(f"--- 块 {i+1} ---")
print(f"内容:\\n{chunk['content']}")
print(f"元数据: {chunk['metadata']}\\n")
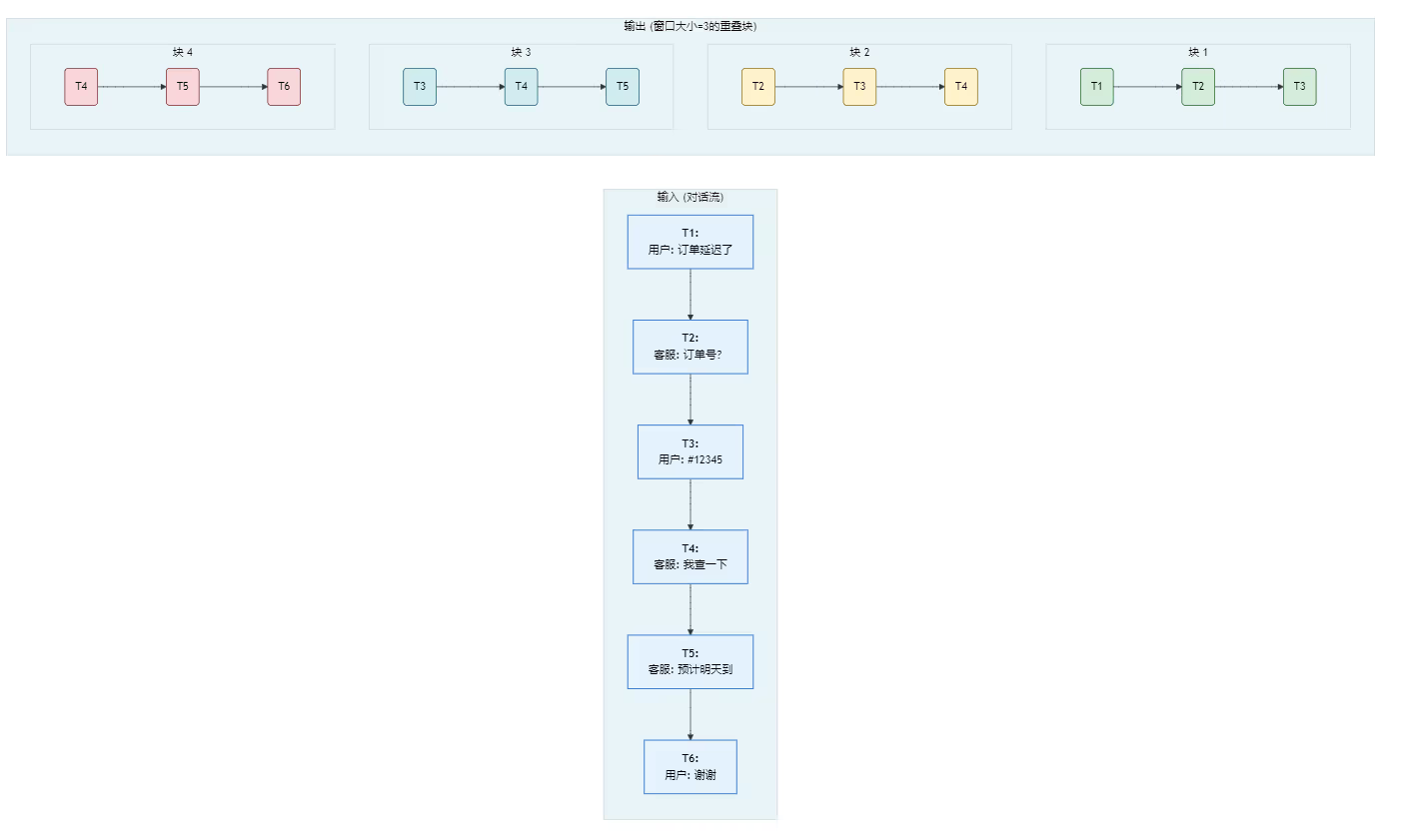
深度剖析:滑动窗口如何维持”记忆”?
对话和时序数据的核心挑战是上下文的连续性 (Context Continuity)。一个孤立的对话片段往往毫无意义。滑动窗口的价值在于,它在数据切分阶段就强制性地保留了这种时间上的连续性。
让我们通过一个对比来理解其重要性。
| 特性 | naïve 切片 (按单句/单轮切分) | 滑动窗口切片 (按窗口重叠) |
|---|---|---|
| 切分依据 | 每个独立的发言(如一个\\n)是一个块。 | N个连续的发言组成一个重叠的块。 |
| 切分结果 | 大量的、上下文孤立的短文本块。 | 数量更少、但每个块都包含一段对话历史。 |
| 上下文连续性 | 完全丧失。每个块都是一个”记忆碎片”。 | 高度维持。每个块都是一段连贯的”记忆录像”。 |
RAG问答场景下的具体影响
假设用户的提问是:“客服说预计什么时候能送到?” 这个问题本身不包含订单号或具体时间。
- 使用 naïve 切片的世界:
-
切分:对话被切分成6个独立的块,其中一块是
[10:05] Support: 确实有些延迟,原因是物流出现了一些意外情况。我们预计明天可以送达。 -
检索:用户的提问向量与这6个块计算相似度。上面的这块内容因为包含了”预计…送达”会获得最高分。系统会返回这个块。
-
生成:LLM得到的上下文仅仅是:“确实有些延迟,原因是物流出现了一些意外情况。我们预计明天可以送达。” LLM无法回答用户的问题,因为它不知道这个回复是针对哪个订单(#12345)的。它可能会回答”预计明天可以送达”,但这是一个不完整且可能产生误导的答案。
- 使用滑动窗口切片的世界:
-
切分:系统生成了包含上下文的块。其中一个块(块3)可能包含了从用户提供订单号到客服最终回复的完整交互:
[10:03] User: 当然,是 #12345。 [10:04] Support: 感谢。我查一下... 好的,看到您的订单了。 [10:05] Support: 确实有些延迟,原因是物流出现了一些意外情况。我们预计明天可以送达。 -
检索:用户的提问向量与这个块计算相似度,因为包含了问题的答案,所以会获得高分并被召回。
-
生成:LLM得到的上下文是一段完整的、包含前因后果的对话。它清楚地知道”预计明天送达”这个信息是针对订单”#12345”的。因此,它可以生成一个完美、准确的答案:“针对订单#12345,客服预计明天可以送达。”
结论:对于时序性数据,滑动窗口通过在块之间制造重叠,保证了时间上下文的完整性。这使得RAG系统能够理解跨越多个轮次的问题和答案,从一个”金鱼记忆”的机器人,变成一个能理解对话历史的智能助手。
召回策略:元数据过滤与语义搜索的协同作战
处理时序性对话数据时,我们的目标是精确找到包含问题答案的那个”对话片段”。滑动窗口和元数据为我们提供了执行”过滤-排序”混合搜索的完美基础。
工作流如下:
-
提问: 用户提出一个带有上下文或限定条件的问题,例如:“帮我找到客服在10:04之后,对订单#12345问题的回复。”
-
元数据预过滤 (Pre-filtering): RAG系统首先解析问题,提取出结构化查询条件。
-
participants必须包含 ‘Support’ -
start_timestamp必须大于 ‘10:04’ 系统使用这些条件,对向量数据库进行元数据过滤,将搜索范围从数百万个块急剧缩小到可能只有几十个相关的块。
-
语义再排序 (Semantic Re-ranking): 在经过滤的小范围结果集上,再执行语义搜索。将问题的剩余部分(“订单问题的回复”)进行向量化,与这几十个块进行相似度计算。
-
返回结果: 返回相似度最高的那个块。
这种”元数据精确定位 + 语义模糊查找”的策略,结合了两种方法的优点,既快又准,是处理日志、对话等半结构化数据的黄金准则。
武器三:代码感知切片 (Code-Aware Chunking) - 解构师
最后,我们来应对技术公司最宝贵的知识资产——代码。
代码不是自然语言。直接对Python或JavaScript代码使用RecursiveCharacterTextSplitter就像让一个不懂语法的人去断句,结果必然是灾难性的。一个函数体可能被拦腰斩断,一个类定义可能被拆得四分五裂,完全破坏了代码的逻辑结构。
代码感知切片的核心思想是:用理解代码语法的方式去切分代码。它利用语言特定的解析器(Parser)将代码转换成一棵抽象语法树(Abstract Syntax Tree, AST)。这棵树精确地表达了代码的结构:类、函数、方法、语句块等等。然后,我们就可以沿着这棵树的脉络进行智能切分。
工作原理:
-
语言检测:确定代码的编程语言(如Python, JavaScript)。
-
AST解析:使用该语言的解析器(如
tree-sitter)将代码字符串解析成AST。 -
按节点切分:沿着AST的节点(如
function_definition,class_definition)进行遍历,将每个完整的逻辑单元(一个函数、一个类)提取为一个独立的块。
代码实战:
LangChain提供了多种语言的AST切片器。
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
# 一段Python代码
python_code = """
def get_user_name(user_id: int) -> str:
\\"\\"\\"Fetches the user's name from the database.\\"\\"\\"
db = connect_to_db()
result = db.query(f"SELECT name FROM users WHERE id = {user_id}")
return result.one()
class DataProcessor:
def __init__(self, data):
self.data = data
def process(self):
# some data processing logic
return len(self.data)
"""
# 初始化Python AST切片器
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=150, # 这里的chunk_size更像一个"软限制"
chunk_overlap=0
)
python_chunks = python_splitter.split_text(python_code)
# 看看切分结果
for i, chunk in enumerate(python_chunks):
print(f"--- 块 {i+1} ---")
print(chunk)
print()
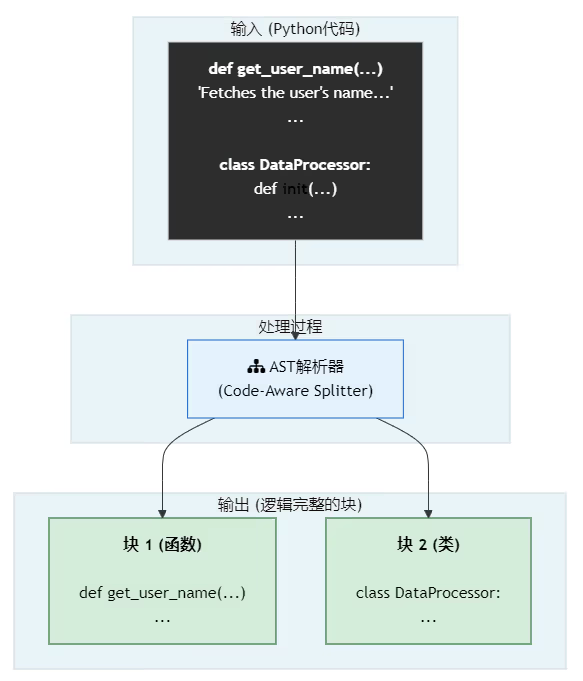
深度剖析:为什么必须”懂代码”?
代码的意义完全蕴含于其结构之中。一个函数的签名、它的文档字符串(docstring)、它的实现,共同构成了一个不可分割的语义单元。
| 特性 | 传统切片 (如 Recursive...) | 代码感知切片 (基于 AST) |
| 切分依据 | 换行符、字符长度。 | 代码的语法结构(函数、类、方法)。 |
| 切分结果 | 语法破碎、上下文丢失的字符串片段。 | 语义完整的、可独立理解的代码单元。 |
| 上下文完整性 | 极低。切分后的块可能无法编译或理解。 | 极高。每个块都是一个逻辑功能体。 |
RAG问答场景下的具体影响
假设开发者的提问是:“如何从数据库获取用户名?”
- 使用传统切片的世界:
-
切分:代码可能会在
db.query那一行被无情地切开。 -
检索:用户的提问可能会匹配到包含
get_user_name的前半部分,但丢失了具体的实现。或者匹配到后半部分,但不知道这个查询是做什么的。 -
生成:LLM得到的上下文支离破碎,无法提供一个完整、可执行的函数作为答案。它可能会幻觉出错误的代码。
- 使用代码感知切片的世界:
-
切分:
get_user_name整个函数被完整地切分为一个独立的块,DataProcessor类被切分为另一个块。 -
检索:用户的提问和函数名、文档字符串(“Fetches the user’s name…“)在语义上高度匹配。系统会精准地召回包含整个
get_user_name函数的那个块。 -
生成:LLM得到了一个完整的、有明确输入输出、并且逻辑自洽的函数代码。它可以直接将这个函数作为答案呈现给开发者,甚至可以附上解释。
结论:处理代码知识时,基于AST的代码感知切片是唯一正确的选择。它尊重代码的内在逻辑,保证了切分后知识单元的完整性和可用性,是构建高质量代码问答、代码生成、代码重构等高级RAG应用的地基。
召回策略:符号、文档字符串与代码体的协同
代码的召回是一个多维度的过程,开发者可能会从不同角度提问:
-
具体实现:“那段用SQL查询用户名的代码在哪?”
-
功能描述:“怎么拿到用户的名字?”
-
函数签名:“我记得有个函数接收
user_id…”
幸运的是,AST切分出的代码块,其本身就包含了这三个维度的信息:
-
代码体 (Code Body):函数的具体实现逻辑。
-
文档字符串 (Docstring):对函数功能的高层自然语言描述。
-
符号与签名 (Symbols & Signature):函数名
get_user_name,参数(user_id: int)。
一个好的代码RAG系统在进行向量检索时,用户的查询向量会同时与这三个部分产生语义共鸣,从而实现精准召回。
Part 3: 核心策略对决与选择指南
我们已经学习了本篇的三种核心武器,加上在《战术篇(上)》中掌握的RecursiveCharacterTextSplitter,我们现在面对的是一个强大的武器库。现在,是时候进行一场”王者对决”,并提供一份终极选择指南,助你在复杂的战场上运筹帷幄。
3.1 策略对决:场景化分析
| 场景 | RecursiveCharacter... | SemanticChunker | AST Splitter | 优胜者 & 原因 |
|---|---|---|---|---|
| 处理一份格式混乱的会议纪要,主题在不同段落间跳跃 | 可能会在对话中间切开,破坏语义。 | 能识别出主题切换的边界,将不同议题分割成独立的、上下文纯净的块。 | 不适用。 | 🏆 **SemanticChunker**: 完美应对语义边界,保证了每个块的主题纯净度。 |
索引一个大型Python项目的所有 **.py** 文件 | 会将函数和类拦腰斩断,产生无意义的代码片段。 | 可能会根据注释和代码行的语义相关性切分,但依然不懂语法。 | 能精确地将每个函数和类提取为独立的、完整的单元。 | 🏆 **AST Splitter**: 唯一尊重代码语法的选择,保证了知识单元的逻辑完整性。 |
| 处理一篇结构良好的博客文章,段落分明 | 表现良好,\\n\\n是很好的分割符,能有效按段落切分。 | 表现同样良好,但可能会因为计算嵌入而产生不必要的开销。 | 不适用。 | 🏆 **Recursive...**: 杀鸡焉用牛刀?对于已有明确结构(段落)的文本,它是最高效、最经济的选择。 |
| 分析大量无格式的用户反馈纯文本 | 只能按固定长度切分,一个反馈可能被切到多个块中,上下文割裂。 | 能将每个用户的独立反馈点(如一个bug报告、一个功能建议)识别并切分出来。 | 不适用。 | 🏆 **SemanticChunker**: 在无结构文本中发现隐藏结构的最佳工具。 |
3.2 最终选择指南
面对一份新的文档,你可以遵循以下决策流程来选择最合适的切分策略:
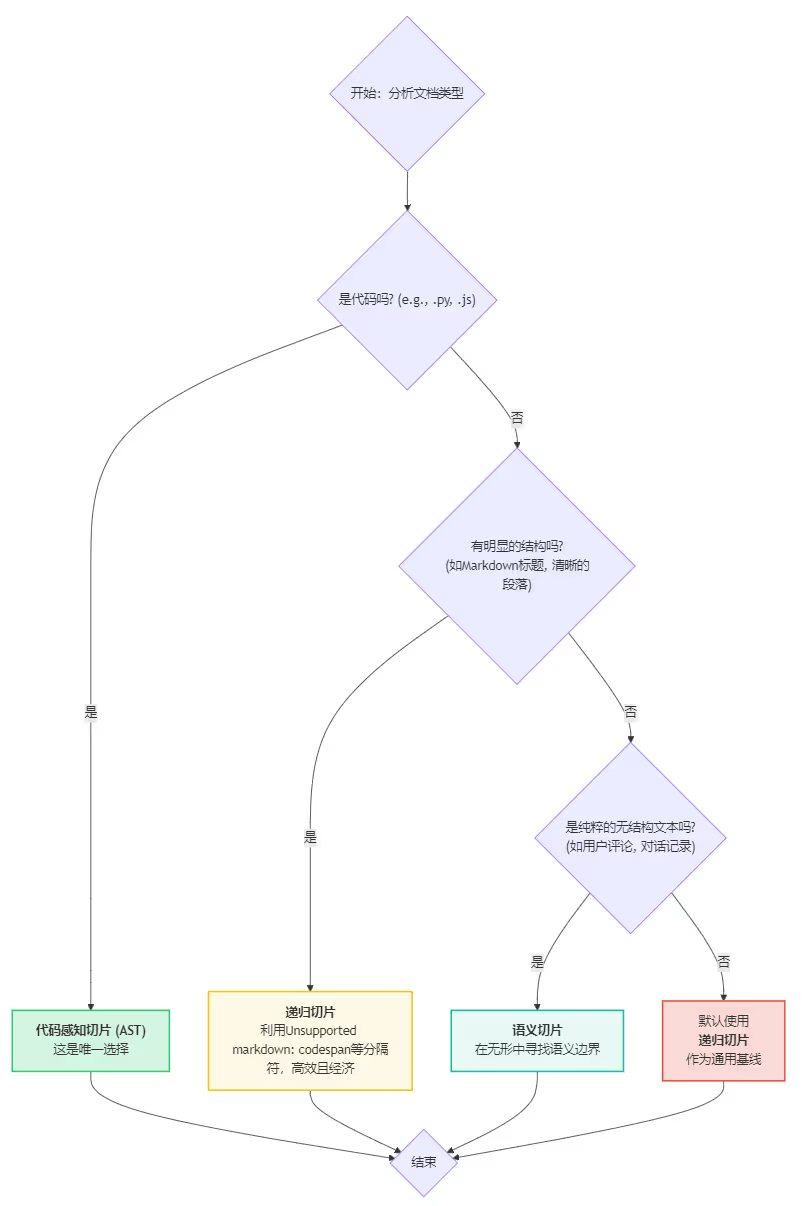
核心思想总结:
-
代码优先:一旦识别出是代码,无条件选择
AST切片。 -
结构次之:如果是非代码文本,优先寻找并利用其现有结构。对于有清晰段落的半结构化文本,
RecursiveCharacterTextSplitter是最高效的选择。 -
语义保底:只有当文本完全没有结构、语义又高度混杂时,才动用
SemanticChunker这把”手术刀”来进行精细的语义解剖。 -
滑动窗口是补充:
滑动窗口并非独立的切片策略,而是一种增强手段。当你使用Recursive或Semantic处理时序性数据(如对话)时,通过设置overlap或自定义窗口逻辑,可以保留上下文连续性。
小结:从知识库到知识图谱的进化
至此,我们已经深入探讨了RAG系统的各种战术细节,从结构化到非结构化,从文本到代码,我们都掌握了精良的武器。你现在已经拥有了构建一个强大的企业级RAG系统所需要的大部分核心技能。
然而,一个真正的专家系统,其知识不仅仅是孤立的文本块,知识之间还存在着复杂的关系。下一篇,也是本系列的技术终章,我们将探讨RAG的终极进化形态:知识图谱(Knowledge Graph)。我们将学习如何从文本中提取实体和关系,构建一个结构化的知识网络,让我们的RAG系统从一个博学的”书呆子”,进化成一个能够进行逻辑推理的”智慧大脑”。敬请期待!